Sunny Balasubramanian
Current quantitative researcher in the crypto & equities space. Formerly at Citadel, AQR, Columbia SEAS '16. Always cracking away at new (sometimes whimsical) problems using different kinds of technology. Please reach out to me at sunny.m.bala@gmail.com if you'd like to chat about any of my prior work or would like to hack on something together. LinkedIn | GitHub
// Projects
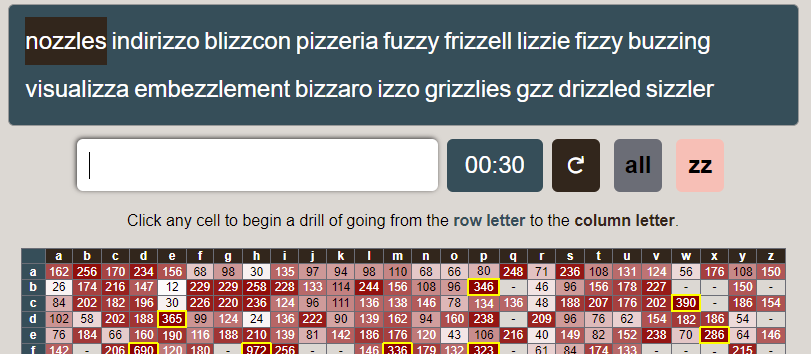
I’ve wanted to make a typing website for a while. My goal was to track typing stats to find weak transitions between letters, then generate drills of real words that let people practice the combinations that they’re slowest at.
BaristArt: Latte Fluid Simulation
The ability to run webGL fluid simulations easily and cross-platform in browsers opens up lots of possibilities for online games. I made this game to showcase how you can make virtual latte art!

Having spent over a decade wandering the streets of Manhattan, I wanted to simulate the results of making random turns at every opportunity.

Charging Airpods with an iPhone
Wouldn’t it be nice if your iPhone could lend some juice to your Airpods? A small hardware project.

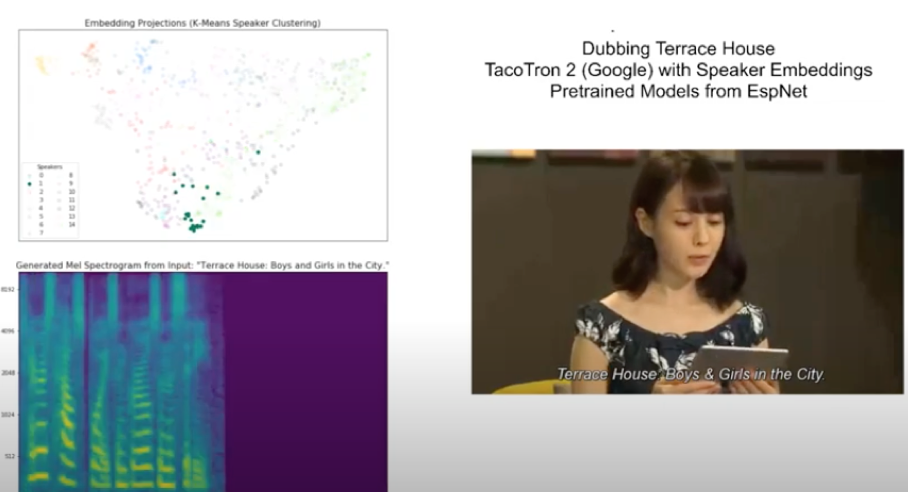
AI Speech Synthesis for Dubbing
Neural networks have been shown as being effective for cloning voices given speech data (ex. creating fake speeches by politicians). Recent multi-speaker networks work in the space of vocal characteristics and therefore no longer require training for each speaker individually. Here, I applied one such network to automatically dub an episode of a Japanese reality show (Terrace House) into English.
I’ve always wanted to play around with an e-ink panel. Commuting via the Metro North every day meant that I spent a of time staring at the board of train times after leaving work to go to the train platform. Here I combined a consumer e-ink panel and a raspberry pi zero in a 3D printed case to mimic the similar device on the platform. It used the MTA API in order to grab the train times and let me glance up next to my monitor to better plan my exit.

Quick build – replacing a wireless charger housing with legos for a more fun look.

Inspired by the Japanese square watermelon which is created by growing into a special mold, I thought it would be fun to learn more about CAD + 3D Printing by applying a similar idea to cucumbers. I grew cucumbers in my apartment and designed a special mold to try and force them into a spherical shape. Unfortunately I didn’t succeed – they just bent.

This was my first hardware project. I connected motors to the knob of an etch-a-sketch and designed a process to reproduce images on the screen by converting the image to a graph representation and traversing it.

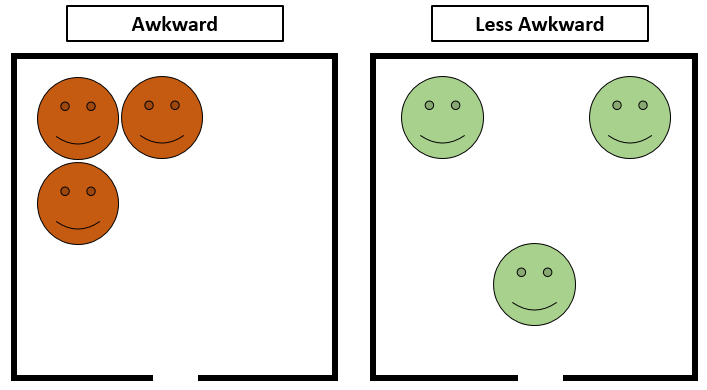
Elevator Awkwardness Minimizer
For a period of time due to construction we could not use the stairs and had to take the elevator in the office. This led to cramped conditions as everyone crowded in. Here, I simulated different numbers of agents within the confines of an elevator that tried to maximize their distance with each other. The result of this was a series of recommendations around where to stand given N people in the elevator.
Senate Insider Trading Investigation
Both Senators and House Representatives are required to disclose financial stock transactions. Some articles came out around this time pointing out suspicious trading activity by a few politicians. A friend and I took the database of XML/PDFs for the Senate data (2013-2017) and created a database using scraping techniques + mechanical turk for difficult to parse entries. Combining with financial data, we were able to investigate suspicious trades on our own. We were able to identify the same instances from the news data. Critically, however, we failed to find evidence that these trades were suspicious in their relative size or even profitability.

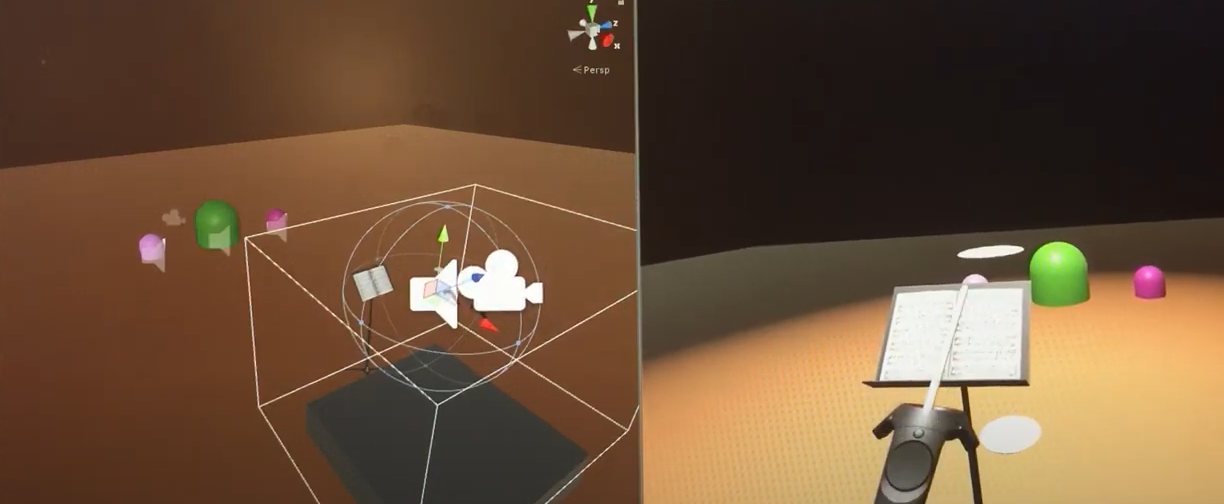
Virtual Reality Conducting Game
As an early adopter of the HTC Vive, I was amazed by the possibilities. For this project I learned how to use the Unity game engine and designed a game to conduct a virtual orchestra. I used MIDI files to get the scores across instruments then allowed the player to control the tempo, volume, and cue-ing individual instruments to come in.
A popular YouTuber put up an alleged video of him slapping himself in the face for 24 hours. I wanted to try using python on video data to verify if the video was legitimate.

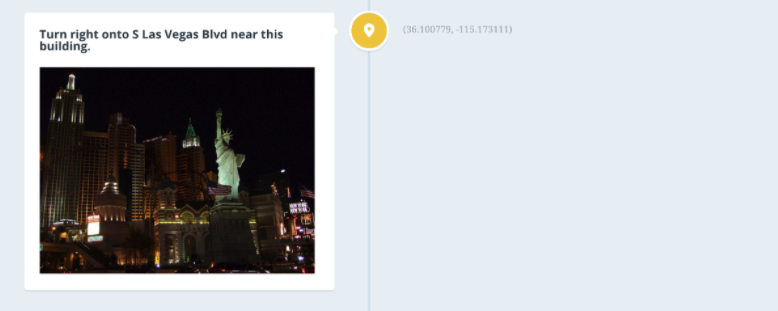
Team project for hackathon. We created a more human-centered directions experience by looking for photos taken near decision points (turns, stops, etc.). Using an image recognition API, when then provided a directions service that gave instructions in ways people typically give each other. The goal was to emulate the feeling of a local telling you “go down this road and turn left at the church.”
AlgoBlues - Markov Chain Music
I had recently learned about markov chains in my probability coursework and looked at applying it to generate blues improvisations over chord structures. By reading in several pages of source material, I was able to build a transition matrix between notes and durations that was appropriate for the key signature. The end result was a piano melody that noodled around while drawing some common themes from the original source.

CUDiningView - Dining Hall Crowdedness (link no longer active)
Team project for a hackathon. We were constantly frustrated by arriving at a crowded dining hall and finding no available seating. The goal was to create a realtime monitor that students could check to find out whether the dining hall was crowded. We convinced Columbia dining administration to send us aggregated swipe counts every 10 minutes. We used this count to model the number of students in the dining hall at any given time. Our model, while simple, made adjustments for longer times for all diners as the occupancy increased.